Wouldn't you like a diagram of Drupal 4.7 with complete data types and referential integrity constraints ? Here's one.
I've long found it annoying to have Drupal use the non-specific data types required by MySQL, instead of the strong typing allowed in ANSI SQL, because it hinders comprehension of the data model by new developers.
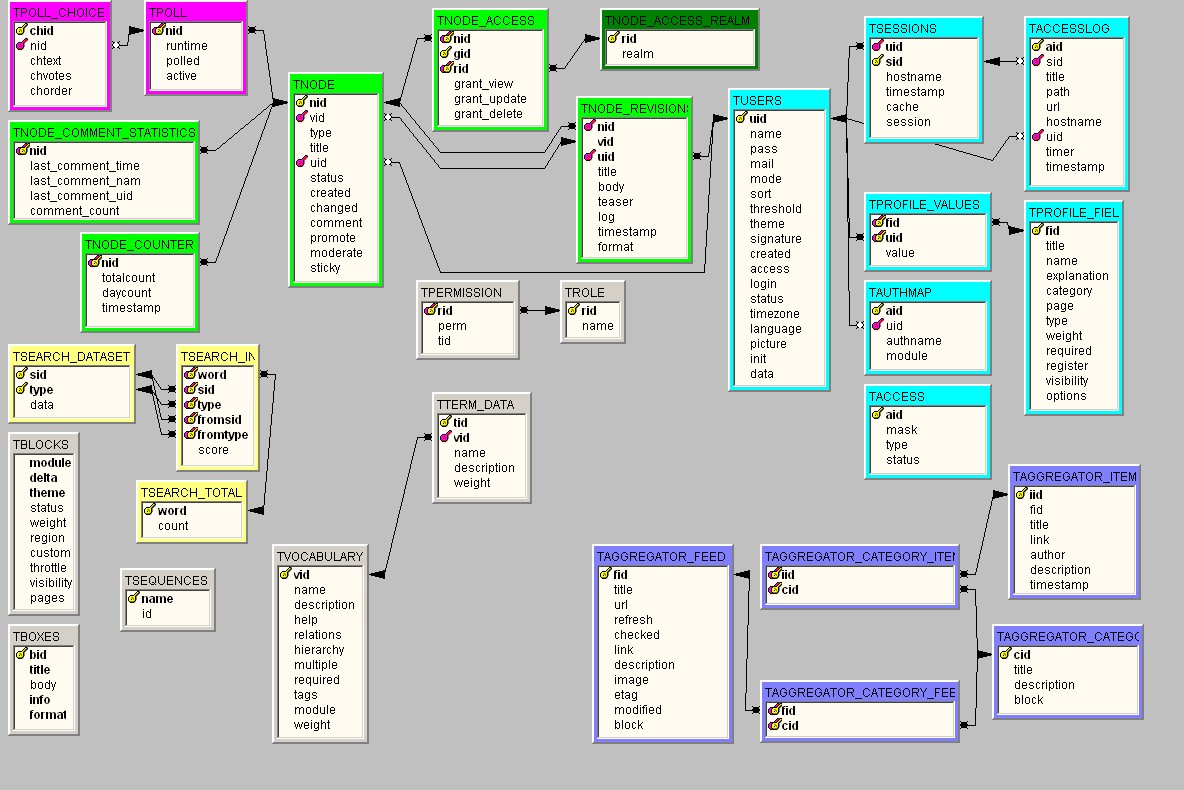 So the next step was to redo the Drupal database schema with a DBMS that understood ANSI SQL domains and referential integrity. Considering my work on Interbase / Firebird, the logical choice was Firebird. So here is the diagram for 4.7 core with Primary Keys (PK) and Foreign Keys (FK) relationships, done with the free-as-beer IBUtils.
So the next step was to redo the Drupal database schema with a DBMS that understood ANSI SQL domains and referential integrity. Considering my work on Interbase / Firebird, the logical choice was Firebird. So here is the diagram for 4.7 core with Primary Keys (PK) and Foreign Keys (FK) relationships, done with the free-as-beer IBUtils.
I've attempted to group tables in logical packages to ease understanding of the model, hence the clashing colors.
Of course, what this means is that there also exist a database.firebird.inc somewhere. But I don't feel it's ready for prime time yet, so I'm not publishing it at the moment. On the other hand, if you want it, just ask me.
A word of warning, though: you'll notice the tnode_access_realm table. This is an Interbase / Firebird artefact, to work around the key size limitation in IB/FB. It might be a good idea to backport it into the standard schemas, though, because it tends to make node access more efficient anyway.
term_node?
Looks nice - Do you have a bigger version?
node_access_realm discussion on groups.drupal.org
Sure
Click to zoom
Silly me, you're right: I
UML model?
Data model done in IBUtils
What I did was :
So, as you see, it's really a result of the Firebird port for Drupal.
One aspect I consider very important is the use of the SQL domains: it's a very important feature for me in Interbase/Firebird as opposed to MySQL because it allows, say, a
UIDto be ofDUIDtype, not justINT(11). And with this, you'll only link it to otherDUIDfields, not to any otherINT(11)because they happen to be of the same size. It's a especially relevant feature when trying to understand the core data model: there are many IDs, and lots of them share the same name:aidandsidspring to mind, but I think there are others. Using domaines differentiates them cleanly while keeping the Drupal naming convention of "one letter + 'id'" for such keys.There's no UML version because my UML diagramming tool (ModelMaker) don't include a DB modeling feature and, AFAIK, E/R modeling has not been standardized in UML.
I see that your model seems to use various stereotypes for this: "table", "PK", "index", and you're using UML method representation for indexes, which might be cleaner than using a straight "index" stereotype on the considered property (as I do on the UML models I've built for other parts of drupal) because it allows for more exact index definitions.
I know there's another diagram a bit like yours somewhere on drupal.org, but it seems to have been there but have been (re)moved recently.
There's more info in the drupal CVS "docs/developer" section.
Using Firebird DB with Drupal
Hi,
I was wondering if you would be able to advise me what I need/should do to use Firebird as a backend to Drupal. Are we able to use your database.firebird.inc or can something like the ADODB database layer written in PHP work?
Thanks,
>> Jerram <<
Two things are needed for a
Two things are needed for a 4.7 port:
IBM's latest article about how they ported Drupal to DB2 gives all the information needed for this type of port, I think. Check it out on Developer Works.
Reserved Firebird Words
Reserved Firebird Words
I think this is partly what the database independence layer will help you achieve.
For instance, redefining
db_prefix_tablesallows you to intervene when the curly braces wrapping table names are processed, at which point you can take advantage of the fact that they've just been identified to rename them to non-conflicting names: instead of just usingstrtras default code does, you could also match on the reserved words to replace them before removing the braces. There might be a better way, though: I'm no expert with this, and I suspect looking at the DB2 version put out by IBM will be enlightening.